코딩테스트에 관심있다면, 시간 복잡도 Big-O에 대해 한번쯤은 들어봤을 것이다. 필자 또한 리스트 탐색은 O(n), 정렬이 된 경우 이분탐색 시 O(log(n))까지 최적화 가능하다는 것은 학습했다. 하지만 문제를 보고 어쩔 때 최적화가 필요할지 판단이 서지 않았었다. 그냥 시간을 줄일 수록 좋은거 아닌가? 라고 막연히 생각했다. 이때 백준 정렬 1~3 문제 간의 비교를 통해 왜 어느 문제는 O(N^2) 으로 통과가 되고, 다른 문제는 O(n*log(n))까지 최적화가 필요한지 알아보겠다.
같은 정렬 문제가 아니다.
다음은 정렬과 관련된 3문제를 캡쳐했다.



박스 표시한 곳을 보면 각기 다른 시간/메모리 제한 그리고 입력개수(N)이 다름을 확인할 수 있다. 정렬 관련 로직은 다양하고 각 상황에 맞는 정렬 로직을 선택할 필요가 있다. 미리 정답을 말하자면 다음과 같다.
- (#2750) 시간 복잡도가 O(n²)인 정렬 알고리즘으로 풀 수 있습니다. 예를 들면 삽입 정렬, 거품 정렬 등이 있습니다.
- (#2751) 시간 복잡도가 O(nlogn)인 정렬 알고리즘으로 풀 수 있습니다. 예를 들면 병합 정렬, 힙 정렬 등이 있지만, 어려운 알고리즘이므로 지금은 언어에 내장된 정렬 함수를 쓰는 것을 추천드립니다.
- (#10989) 수의 범위가 작다면 카운팅 정렬을 사용하여 더욱 빠르게 정렬할 수 있습니다.
그럼 요구사항을 보고 어떤 알고리즘을 적용해야할지? 왜 내 로직은 시간초과가 걸리는지? 판단하는 방법을 배워보자.
CPU 성능
갑자기 왠 CPU? 라는 생각이 들 수 있다. (좀만 기다려 달라. 곧 아하 모먼트가 올 것이다! (。•̀ᴗ-)✧) 코테 문제를 풀다보니 1초에 10^8번의 연산이 가능하다는 말을 주워들었다. 하지만, 그 이유를 모르겠어서 우선 GPT에게 물어보았다.

요약하자면,
- 오늘날 CPU는 GHz 단위로 작동한다.
- 1GHz = 1초당 10^9번의 사이클 (=10억)
- 1사이클 = 기본적인 연산(+,-,*,/) 가능
즉, 일반적인 CPU는 1초에 10^9 연산이 가능하다.
Q. 어디서는 1초에 10^8 연산이 가능하다는데요?
A. 필자 또한 헷갈렸던 부분인데 10 상수곱의 여유분을 두고 10^9 = 10*10^8, 10^8 연산이 가능하다고 말하는 것 같다.
문제 분석하기
다시 문제로 돌아와서, 시간제한과 입력갯수(=N)을 분석해보자.
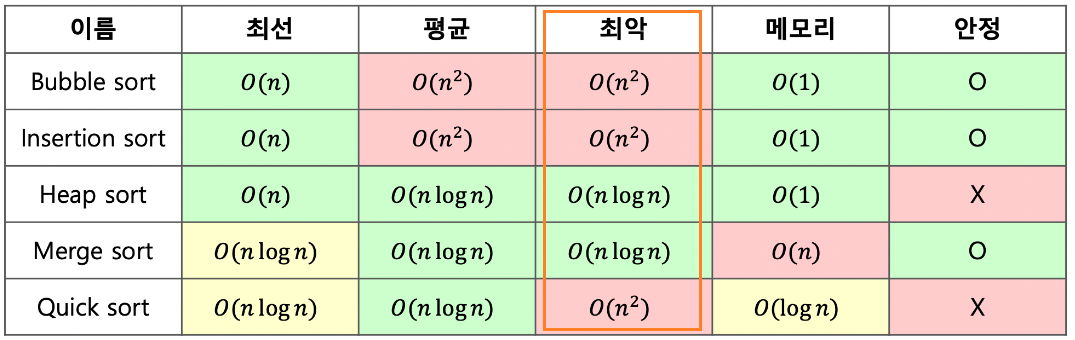
#2750 시간제한=1초, N<=10^3 , 메모리 제한=128MB
- (가능) O(n^2); 버블정렬, 삽입정렬, 퀵소트(최악)
- (가능) O(nlog(n)) : 힙정렬, 합병정렬
가장 for문 2개를 사용하며 정렬 알고리즘은 대체로 O(N^2) 시간복잡도를 갖는다.
O((10^3)^2) = O(10^6) < O(10^9) 즉, 1초 내에 풀 수 있다.
그리고 보다 빠른 O(nlog(n)) 은 당연히 적용 가능하다.
#2750 시간제한=2초, N<=10^6, 메모리 제한=256MB
- (불가능) O(n^2); 버블정렬, 삽입정렬, 퀵소트(최악)
- (가능) O(nlog(n)) : 힙정렬, 합병정렬
자, 입력 개수가 커졌다. O(n^2)을 선택하면, O((10^6)^2) = O(10^12) > O(10^9) 10^3*1초 = 약 1000초가 걸린다.
O(nlog(n)) = 10^6 * 6 * log 10 < O(10^9)
이게 바로 O(nlog(n)) 알고리즘을 선택해야하는 이유다.
#10989 시간제한=5초, N<=10^7, 메모리 제한=8MB
사실 이 문제는 시간 복잡도보다는 '메모리 제한' 이 초점이 맞춰진 문제다. 왜냐하면, 시간은 5초이므로 O(n*log(n)) 로 충분히 풀 수 있다. 하지만 타 문제와 달리 메모리 제한이 극도로 제한되어 있다. 정답은 '계수 정렬 알고리즘'을 사용해야한다. 아직 메모리 분석 방법은 공부하지 못하기도 했고 해당 알고리즘은 별도로 포스팅하겠다.
최적화 꼭 필요한가?
이처럼 입력개수와 시간제한을 통해 왜 시간복잡도를 신경쓰며 적절한 알고리즘을 선택해야하는지 알아보았다. 더 나아가 더 최적화하는 방법도 알아보면 좋겠지만, 필자는 사실 구현과 통과에 급급하다 보니 아직 최적화에 익숙치 않다. 하지만 타 유저의 제출 현황을 보면 정말 극강의! 최적화를 추구하는 유저가 있음을 보고 방법이 무엇일지 궁금했다.
최근 동료들과 리뷰를 하면서 몇가지 팁을 얻었다.
- 반복문 줄인다.
- input 대신 sys.stdin.readline(), print 대신 sys.stdout.write()
- 로컬변수 반복 할당을 줄이기 위해 함수를 정의하기; 일례로 반복문으로 누적합 구하는것보다 sum method 를 이용한게 더 빨랐다. 주의할 점은 함수 내에 global 변수를 사용하면 오히려 더 시간복잡도가 증가했다.
- (더 알아볼 것) 변수 스코프, 메모리구조, 할당 과정
- binary_search vs two pointer; 물론 분할 size에 따른 차이라고 볼 수도 있는데, binary_search 는 우선 size//2 씩 진행하므로 O(logN) 탐색을 할 수 있으므로 꼭 잊지 말자.
- to be continued...
- print > sys.out writeline
- 지역에서 전역으로 찾고찾고 가는건 오래걸리는 이유; 네임 스페이스
- N queen 노션 참고
끝으로, 정렬 문제가 더 있다. 시간 복잡도 분석 후 알고리즘을 선택하는 재밌는 학습 경험을 하시길!
'2️⃣ 개발 지식 B+ > 코딩 테스트' 카테고리의 다른 글
| [백준/python] DP 유형 - 배낭(Knapsack) 문제 (0) | 2024.08.26 |
|---|---|
| [백준/python] DP 유형 - LIS & LDS 그리고 LCS (0) | 2024.08.26 |
| [백준/python] stack 유형 모음집 및 접근 컨셉 (0) | 2024.08.21 |
| [알고리즘/python] 위상정렬 (0) | 2024.08.19 |
| [자료구조/python] stack, queue (0) | 2024.08.16 |



